Změna nastala až s nástupem počítačové techniky, kdy začalo být nutné do počítačů nějak zaznamenávat háčková a čárková písmena. Vznikly různé způsoby kódování češtiny iso-8859-2, dosLatin2-cp852, windows-cp1250, kromě bratří Veverků máme i bratry Kamenický... Nejen že se psaní češtiny zařadilo hned vedle čínštiny a arabštiny, ale vznikl v tom ještě nesmírný binec.
Český národ proto celkem pochopitelně Mr. Jana Husa přestává mít rád a zvláště mezi některými programátory se dokonce objevují názory, že ho měli upálit dřív než ty háčky a čárky stačil vymyslet.
Program HUS je malým příspěvkem k rehabilitaci tohoto velkého Čecha. Snaží se napravovat problémy, které nám Mr. Jan Hus zavedením diakritiky způsobil.
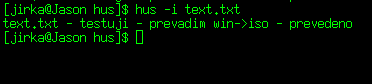
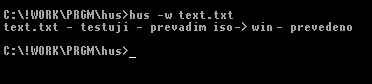
Zvládá češtinu ve všech nejčastěji používaných kódováních, dokonce i v moderním unicod utf-8. Umí převádět rámečky z dosového kódování, současně převádí i konce řádků. Je vybaven polointeligentní autodetekcí, ve většině případů sám správně pozná v jakém kódování text je. U html souborů automaticky upravuje v hlavičce charset=...
Kromě všech možných běžně požívaných druhů kódování češtiny umí Hus ještě několik specialit:
Zjednodušeně řečeno: zcela volné i pro komerční využití, můžete to kopírovat, šířit, rozdávat, ale i prodávat dle libosti. K dispozici je i zdrojový kód.
Můžete si to dokonce i upravovat a předělávat, jak chcete. S jedinou podmínkou: výsledný upravený program musí být stejně volně šiřitelný včetně zdrojového kódu.
Podrobnosti o licenci česky, anglicky.
(c) 2002-2013 Jirka Bubenicek